跳到内容
 An increasingly massive number of remote-sensing images spurs the development of extensible object detectors that can detect objects beyond training categories without costly collecting new labeled data. In this paper, we aim to develop open-vocabulary object detection (OVD) technique in aerial images that scales up object vocabulary size beyond training data. The performance of OVD greatly relies on the quality of class-agnostic region proposals and pseudo-labetls for novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework following the student-teacher self-learning mechanism employs the RemoteCLIP model as an extra omniscient teacher with rich knowledge. By doing so, our approach boosts not only novel object proposals but also classification. Furthermore, we devise a dynamic label queue strategy to maintain high-quality pseudo labels during batch training. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 46.5% mAP on VisDroneZSD novel categories, which outperforms the state-of-the-art open-vocabulary detectors by 21.0% mAP. To our best knowledge, this is the first work to apply and develop the open-vocabulary object detection technique for aerial images. The code is available at https://github.com/lizzy8587/CastDet.[......]
An increasingly massive number of remote-sensing images spurs the development of extensible object detectors that can detect objects beyond training categories without costly collecting new labeled data. In this paper, we aim to develop open-vocabulary object detection (OVD) technique in aerial images that scales up object vocabulary size beyond training data. The performance of OVD greatly relies on the quality of class-agnostic region proposals and pseudo-labetls for novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework following the student-teacher self-learning mechanism employs the RemoteCLIP model as an extra omniscient teacher with rich knowledge. By doing so, our approach boosts not only novel object proposals but also classification. Furthermore, we devise a dynamic label queue strategy to maintain high-quality pseudo labels during batch training. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 46.5% mAP on VisDroneZSD novel categories, which outperforms the state-of-the-art open-vocabulary detectors by 21.0% mAP. To our best knowledge, this is the first work to apply and develop the open-vocabulary object detection technique for aerial images. The code is available at https://github.com/lizzy8587/CastDet.[......]继续阅读
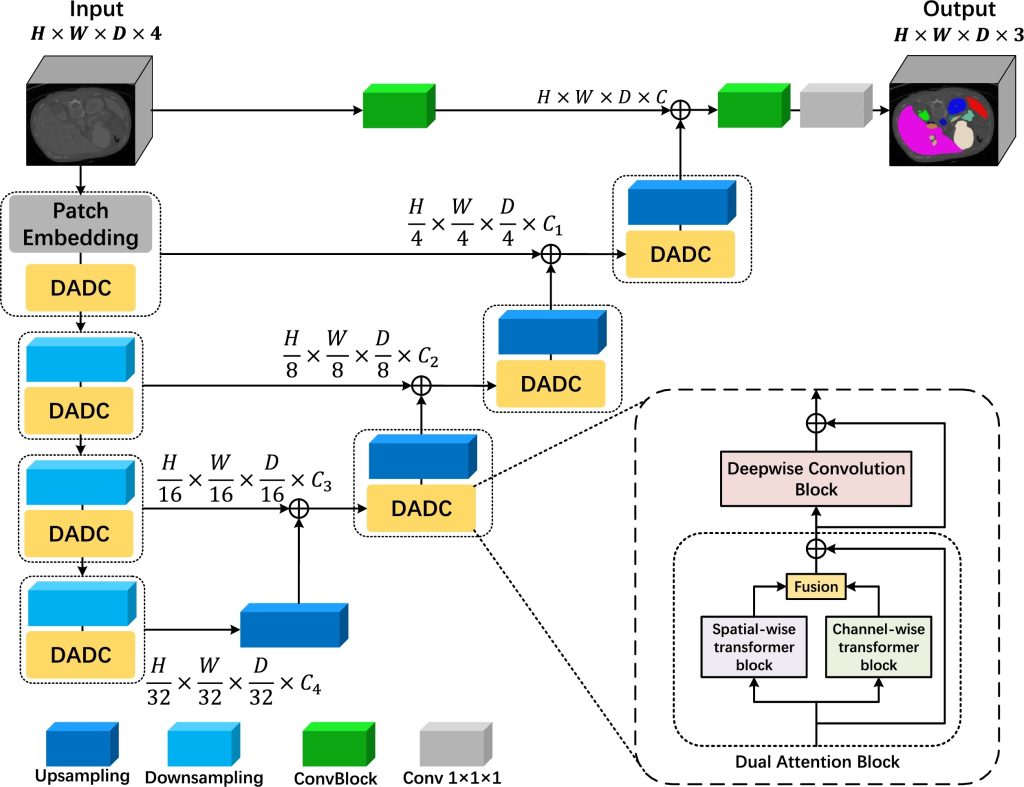 Existing approaches to 3D medical image segmentation can be generally categorized into convolution-based or transformer-based methods. While convolutional neural networks (CNNs) demonstrate proficiency in extracting local features, they encounter challenges in capturing global representations. In contrast, the consecutive self-attention modules present in vision transformers excel at capturing long-range dependencies and achieving an expanded receptive field. In this paper, we propose a novel approach, termed SCANeXt, for 3D medical image segmentation. Our method combines the strengths of dual attention (Spatial and Channel Attention) and ConvNeXt to enhance representation learning for 3D medical images. In particular, we propose a novel self-attention mechanism crafted to encompass spatial and channel relationships throughout the entire feature dimension. To further extract multiscale features, we introduce a depth-wise convolution block inspired by ConvNeXt after the dual attention block. Extensive evaluations on three benchmark datasets, namely Synapse, BraTS, and ACDC, demonstrate the effectiveness of our proposed method in terms of accuracy. Our SCANeXt model achieves a state-of-the-art result with a Dice Similarity Score of 95.18% on the ACDC dataset, significantly outperforming current methods.[......]
Existing approaches to 3D medical image segmentation can be generally categorized into convolution-based or transformer-based methods. While convolutional neural networks (CNNs) demonstrate proficiency in extracting local features, they encounter challenges in capturing global representations. In contrast, the consecutive self-attention modules present in vision transformers excel at capturing long-range dependencies and achieving an expanded receptive field. In this paper, we propose a novel approach, termed SCANeXt, for 3D medical image segmentation. Our method combines the strengths of dual attention (Spatial and Channel Attention) and ConvNeXt to enhance representation learning for 3D medical images. In particular, we propose a novel self-attention mechanism crafted to encompass spatial and channel relationships throughout the entire feature dimension. To further extract multiscale features, we introduce a depth-wise convolution block inspired by ConvNeXt after the dual attention block. Extensive evaluations on three benchmark datasets, namely Synapse, BraTS, and ACDC, demonstrate the effectiveness of our proposed method in terms of accuracy. Our SCANeXt model achieves a state-of-the-art result with a Dice Similarity Score of 95.18% on the ACDC dataset, significantly outperforming current methods.[......]继续阅读
 Oracle bone script is an ancient form of writing character used by ancient Chinese. It takes advantage of static pictographic elements to shape scenes, thus conveying dynamic and prosperous messages. The purpose of this study is to demonstrate that scene-based icons inspired by the oracle bone script can be effectively recognized and understood by people from different cultures and thus used to help in cross-cultural communication scenarios. An experiment was conducted with a sample of 16 people from different cultural backgrounds to determine the icons’ recognizability. The result indicates that these icons have relatively high recognizability in a cross-cultural context.[......]
Oracle bone script is an ancient form of writing character used by ancient Chinese. It takes advantage of static pictographic elements to shape scenes, thus conveying dynamic and prosperous messages. The purpose of this study is to demonstrate that scene-based icons inspired by the oracle bone script can be effectively recognized and understood by people from different cultures and thus used to help in cross-cultural communication scenarios. An experiment was conducted with a sample of 16 people from different cultural backgrounds to determine the icons’ recognizability. The result indicates that these icons have relatively high recognizability in a cross-cultural context.[......]继续阅读
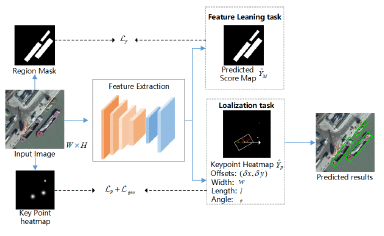 Accurate and efficient ship detection in remote sensing images still remains a challenging task due to the large variations of scales, orientations and distributions. In this paper, we propose an anchor-free ship detector that directly regresses ship localization parameters, offering a simpler pipeline over the previous methods. The detection network is then trained in a multi-task fashion which contains not only the ship center-point maps and oriented bounding boxes but the ship masks. Instead of fixing the weights among the multiple task losses, we adopt a curriculum learning strategy which gradually adapts the loss weights during the training process so that the network can learn the discriminative ship features at the early stage and obtain more localization information while training continues. Experimental results on real dataset demonstrate the effectiveness and efficiency of our proposed method.[......]
Accurate and efficient ship detection in remote sensing images still remains a challenging task due to the large variations of scales, orientations and distributions. In this paper, we propose an anchor-free ship detector that directly regresses ship localization parameters, offering a simpler pipeline over the previous methods. The detection network is then trained in a multi-task fashion which contains not only the ship center-point maps and oriented bounding boxes but the ship masks. Instead of fixing the weights among the multiple task losses, we adopt a curriculum learning strategy which gradually adapts the loss weights during the training process so that the network can learn the discriminative ship features at the early stage and obtain more localization information while training continues. Experimental results on real dataset demonstrate the effectiveness and efficiency of our proposed method.[......]继续阅读
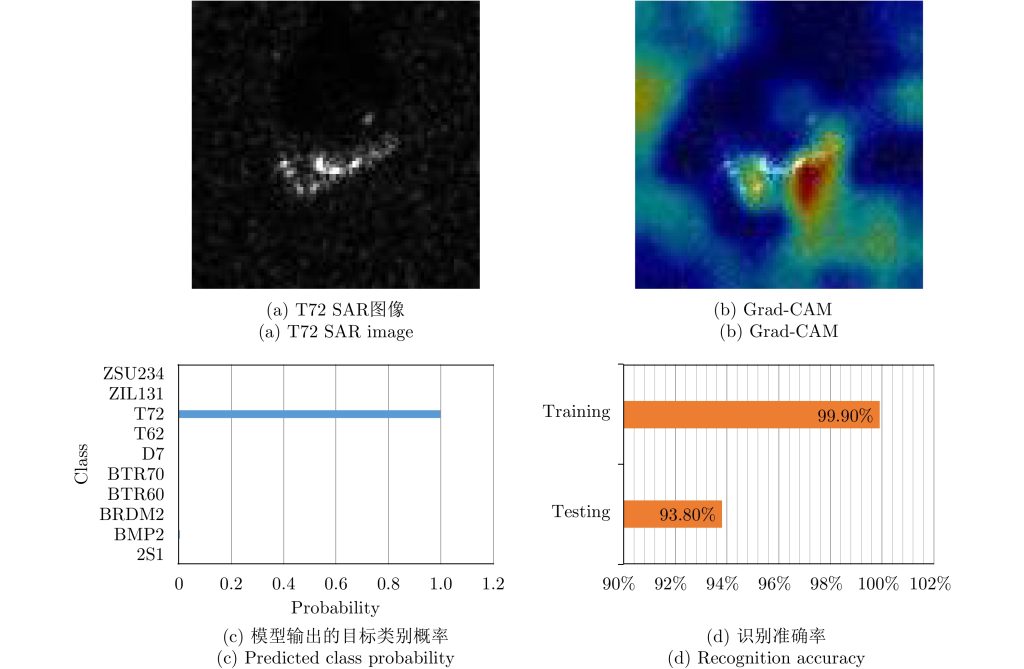 合成孔径雷达(SAR)图像目标识别是实现微波视觉的关键技术之一。尽管深度学习技术已被成功应用于解决SAR图像目标识别问题,并显著超越了传统方法的性能,但其内部工作机理不透明、解释性不足,成为制约SAR图像目标识别技术可靠和可信应用的瓶颈。深度学习的可解释性问题是目前人工智能领域的研究热点与难点,对于理解和信任模型决策至关重要。该文首先总结了当前SAR图像目标识别技术的研究进展和所面临的挑战,对目前深度学习可解释性问题的研究进展进行了梳理。在此基础上,从模型理解、模型诊断和模型改进等方面对SAR图像目标识别的可解释性问题进行了探讨。最后,以可解释性研究为切入点,从领域知识结合、人机协同和交互式学习等方面进一步讨论了未来突破SAR图像目标识别技术瓶颈有可能的方向。[......]
合成孔径雷达(SAR)图像目标识别是实现微波视觉的关键技术之一。尽管深度学习技术已被成功应用于解决SAR图像目标识别问题,并显著超越了传统方法的性能,但其内部工作机理不透明、解释性不足,成为制约SAR图像目标识别技术可靠和可信应用的瓶颈。深度学习的可解释性问题是目前人工智能领域的研究热点与难点,对于理解和信任模型决策至关重要。该文首先总结了当前SAR图像目标识别技术的研究进展和所面临的挑战,对目前深度学习可解释性问题的研究进展进行了梳理。在此基础上,从模型理解、模型诊断和模型改进等方面对SAR图像目标识别的可解释性问题进行了探讨。最后,以可解释性研究为切入点,从领域知识结合、人机协同和交互式学习等方面进一步讨论了未来突破SAR图像目标识别技术瓶颈有可能的方向。[......]继续阅读
 设计说明: 在这个数据过载的时代, 信息可视化如同天文学家的望远镜和生物学家的显微镜, 是将数据处理成易于人脑理解和吸收形式的工具. 我们接触到的数据, 常常是每个数据项具有两个以上属性值的高维数据; 而我们常用的纸媒和屏幕, 只有物理上的两个显示信息的维度, 对于高维数据的呈现有着一定局限性.[......]
设计说明: 在这个数据过载的时代, 信息可视化如同天文学家的望远镜和生物学家的显微镜, 是将数据处理成易于人脑理解和吸收形式的工具. 我们接触到的数据, 常常是每个数据项具有两个以上属性值的高维数据; 而我们常用的纸媒和屏幕, 只有物理上的两个显示信息的维度, 对于高维数据的呈现有着一定局限性.[......]继续阅读
 In this paper, we propose a vision-based hand gesture recognition system for human-computer interaction. The gesture recognition systems are employed in developing a rock-paper-scissors game between human and our robotic hands in realtime. Our task is to predict the gestures as soon as possible by using high-speed cameras. Due to the computational complexity, the standard long-term recurrent convolution network-based action classification system cannot be contented with classification tasks based on high-speed cameras. We propose to address this issue by employing a more efficient network architecture and using a threshold-based method to predict the gesture in advance. We validate our proposed method on the new gesture dataset for the rock-paper-scissors game. The model is able to successfully learn gestures varying in duration and complexity. A comparative analysis of CNN and long-term recurrent convolution network is performed. We report a gesture classification accuracy of 97% and report a near real-time computational complexity of 7 ms per frame.[......]
In this paper, we propose a vision-based hand gesture recognition system for human-computer interaction. The gesture recognition systems are employed in developing a rock-paper-scissors game between human and our robotic hands in realtime. Our task is to predict the gestures as soon as possible by using high-speed cameras. Due to the computational complexity, the standard long-term recurrent convolution network-based action classification system cannot be contented with classification tasks based on high-speed cameras. We propose to address this issue by employing a more efficient network architecture and using a threshold-based method to predict the gesture in advance. We validate our proposed method on the new gesture dataset for the rock-paper-scissors game. The model is able to successfully learn gestures varying in duration and complexity. A comparative analysis of CNN and long-term recurrent convolution network is performed. We report a gesture classification accuracy of 97% and report a near real-time computational complexity of 7 ms per frame.[......]继续阅读
